Keywords as Identifiers
As you write your grammar, you will add keywords such as var, get or function to improve the readability of your language and to add structure.
These keywords get a special keyword highlighting whenever they are used, by default even at unintended locations according to your grammar, and are handled separately from other terminals such as names, identifiers, numbers and so on.
You will quickly notice that a function such as function get() will lead to parser errors by default, as get is identified as keyword and not as identifier.
This guide is all about how to explicitly enable these keywords (highlighted in blue) to be supported as identifiers (highlighted in white) as well.
Let’s look at the “hello-world” example in the playground or as a new local project created with yo langium (for details, how to set up your first Langium project, read getting started):
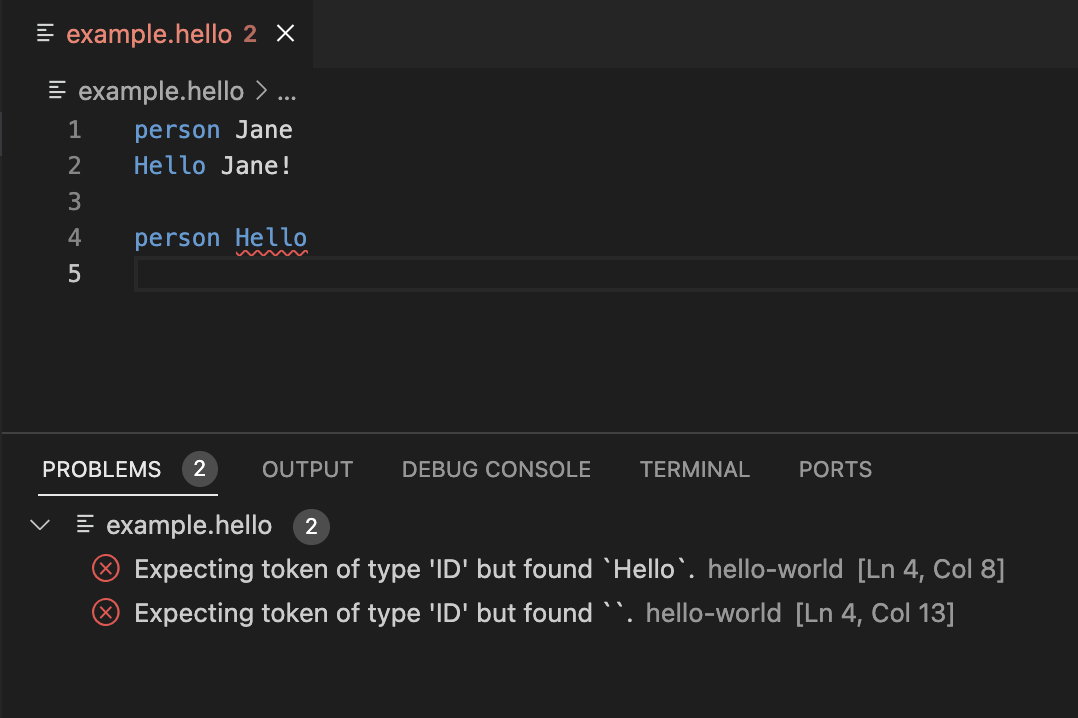
Here, it is not possible to introduce a person whose name is “Hello”, since Hello is a dedicated keyword of the language. Additionally, we cannot greet a person called “Hello” as well.
The same applies to the keyword “person”, but let’s focus on enabling “Hello” as name for persons.
To enable keywords as identifiers, you need to apply the following three steps:
The first step is to modify the grammar to explicitly parse keywords as property values. At the moment, the parser rule for introducing persons looks like this:
Person: 'person' name=ID;
terminal ID: /[_a-zA-Z][\w_]*/;
Note that the terminal rule for ID already covers the string “Hello”.
However, since the parser rule for greeting persons uses “Hello” as keyword, the keyword takes precedence:
Greeting: 'Hello' person=[Person:ID] '!';
Roughly summarized, the background for this behaviour is that Langium’s internally used LL(k) parser implementation named Chevrotain first does lexing/tokenizing, i.e. splitting text into single tokens, such as keywords, identifiers and delimiters.
The actual parsing, i.e. the application of the parser rules, is performed afterwards on these tokens.
Chevrotain uses regular expressions (regex) for splitting text into tokens.
Since keywords are implemented as regex as well and take precedence, all occurrences of “Hello” are treated as keywords for the parser rule named Greeting,
even a “Hello” intented to be a name, which finally causes the two syntax errors.
In order to explicitly enable parsing “Hello” as name as well, modify the parser rule for persons in this way:
Person: 'person' name=(ID | 'Hello');
terminal ID: /[_a-zA-Z][\w_]*/; // the terminal rule for ID is unchanged!
Now Langium knows that keyword “Hello” may also occur as value for the name property of the parser rule for persons.
That’s it! (Don’t forget to run npm run langium:generate after updating the grammar.)
Since the name property is used for cross-references by the parser rule for greetings, “Hello” needs to be supported here as well. For that we recommend to introduce a data type rule like “PersonID” in the example, since it makes it easier to support more keywords in the future:
Person: 'person' name=PersonID;
Greeting: 'Hello' person=[Person:PersonID] '!';
PersonID returns string: ID | 'Hello';
Now, your editor accepts “Hello” as value for persons' names. Nevertheless, the name “Hello” still is highlighted in blue and looks like a keyword “Hello”. This leads us to the second step.
The second step is to change the semantic type of the resulting token in order to adjust the highlighting in the editor: While parsing text with Langium is done in a language server, the highlighting is done in editors (the language clients). Editors like VS Code usually use syntax highlighting basing on the tokenized text. This highlighting can be complemented by semantic highlighting with additional semantic types for the tokens from the language server.
In case of Langium and VS Code, VS Code uses by default TextMate grammars, which can be seen as collections of regex (and which is generated by npm run langium:generate), to split the text into tokens and to assign a (syntactic) type to these tokens. The color for highlighting the token is chosen depending on the assigned type.
In the example, a regex for the “Hello” keyword matches all strings “Hello” in text, resulting in the blue color even for “Hello” used as name.
Since Langium applies the parser rules to the token stream, Langium is able to distinguish “Hello” tokens used as keyword for greetings and “Hello” tokens used as name for persons and therefore is able to assign different semantic types to “Hello” tokens for persons and for greetings. According to the Language Server Protocol (LSP), these semantic token types are sent to editors like VS Code, which complement the syntactic types of tokens with these semantic types. The default highlighting of tokens according to the syntactic type is then altered according to the semantic token type and the color theme selected by the user (editor preferences).
In Langium, the SemanticTokenProvider service is responsible for assigning language-dependent semantic types to tokens.
Therefore, we customize the default semantic token provider like this:
import { AstNode } from 'langium';
import { AbstractSemanticTokenProvider, SemanticTokenAcceptor } from 'langium/lsp';
import { isPerson } from './generated/ast.js';
import { SemanticTokenTypes } from 'vscode-languageserver';
export class HelloWorldSemanticTokenProvider extends AbstractSemanticTokenProvider {
protected override highlightElement(node: AstNode, acceptor: SemanticTokenAcceptor): void {
if (isPerson(node)) {
acceptor({
node,
property: 'name',
type: SemanticTokenTypes.class
});
}
}
}
For all persons (isPerson(...) in line 7), we explicitly specify the semantic type for the token of their 'name' property.
Here, we use SemanticTokenTypes.class as semantic type.
For your case, select a predefined type which fits your domain best.
Since the name is used as cross-reference by greetings, a similar check and assignment of a semantic token type needs to be done for the person property of Greeting as well.
After creating the semantic token provider, you need to register the HelloWorldSemanticTokenProvider in hello-world-module.ts in the following way:
export const HelloWorldModule: Module<HelloWorldServices, PartialLangiumServices & HelloWorldAddedServices> = {
// ...
lsp: {
SemanticTokenProvider: (services) => new HelloWorldSemanticTokenProvider(services)
}
};
Now rebuild and restart your application and test the improvements of the second step:
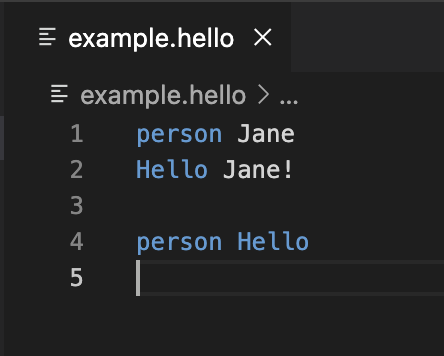
The HelloWorldSemanticTokenProvider works, and you might see a different highlighting XOR you might not see any difference, e.g. “Hello” is still blue here. This leads us to the third step.
The third step is to ensure that your editor supports the assigned semantic tokens:
Depending on your editor and the currently selected color theme, the semantic token type selected in HelloWorldSemanticTokenProvider might not be supported or didn’t get a different color in the color theme.
The easiest way to detect such problems is to change the current color theme and to try some others.
Note that VS Code allows to switch off semantic highlighting for all themes with the setting editor.semanticHighlighting.enabled.
After switching from “Dark (Visual Studio)” to “Dark Modern” in VS Code, the example looks as expected.
You can switch the current color theme in VS Code with cmd + K cmd + T (or via the menu: Code -> Settings… -> Theme -> Color Theme).
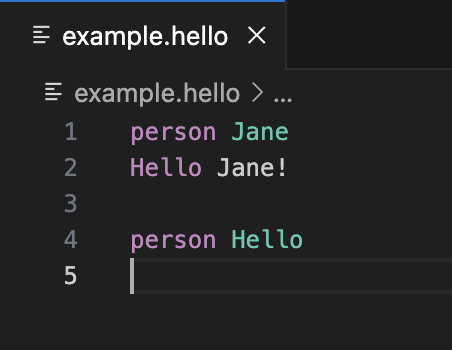
Now “Hello” is highlighted in purple if used as keyword, it’s written in green if it is used as value for the name of a person. Another solution is to select a different semantic type for your token in step two.
While step one is mandatory to enable keywords as values in general, step two improves the user experience of your language. While step one and step two can be handled in the LSP server once for your language, step three highly depends on your editor and its color themes (in the LSP clients), which makes step three quite complicated to handle.
Now you have learned how to enable keywords as regular values for properties. Feel free to enable the keyword “person” as name for persons in the example on your own.
Word to the wise: Enabling certain strings to be used interchangeably as keywords and identifiers/values is possible, but has some costs. It always needs to be evaluated per case, whether accepting the costs is required and worth it. Additionally, using keywords as identifiers impacts the user experience, therefore, involve the users of your language!
Some hints beyond this guide:
- In multi-grammar projects, only keywords of the included grammars are affected by this general problem, but not keywords of other languages or Langium grammar files.
- In order to get an overview about the keywords of your language, have a look into the generated TextMate grammar
*.tmLanguage.jsonand search for the pattern namedkeyword.control.*, which contains a regex with the keywords. - Read about the concept of semantic tokens in the Language Server Protocol (LSP) including predefined semantic types for tokens.
- Read about how VS Code realizes semantic highlighting using semantic tokens.
- Dive into tokenizing of Chevrotain with regex.